Progress Update #1
March 11, 2019
Goals
My goals for the first week were to create an autoencoder model that could compress live video from a forward facing camera on a car. The autoencoder will be used to compress images so a secondary model can make steering descisions on a smaller input. I broke down the goal into these few points:
- Create a small dataset of highway driving images
- Create a initial model to be used as an autoencoder
- Train the model and observe results
Getting Started
I began by setting up the working enviroment. I knew I’d be using python as the primary language for developing this as it is known for rapid prototyping abilities and a large variety of machine learning libraries and resources. I will be using keras with a tensorflow backend.
Dataset collection
For the initial dataset I aimed to collect atleast 5000 images of size 200 by 200 pixels. I created a script that would capture a section of the screen on a computer. For the data to be useful in a machine learning model the image had to be converted to grayscale and resized to the correct size.
Here are some samples of collected images being used in the dataset. They have been resized and converted to grayscale.
Model
The model I will be using will be a type of autoencoder. As a brief overview an autoencoder works by compressing an image down to a smaller but meaningful representation. After compression it rebuilds the image from the smaller model only. The accuracy of the autoencoder is measured by the difference in original image and its reconstruction. Heres a general autoencoder:

The graph of a traditional autoencoder on a very small imput may look like this:

This graph has 6 inputs and 6 outputs, with the layers inbetween there are a total of 72 connections between neurons. The images in the collected dataset are 200x200 meaning there are 40000 inputs. With the layers inbetween there would be over 140000000 connections between neurons making it impossible to simulate on my computer in a reasonable amount of time. Luckily this problem has a very effective solution, layers that are specialized for images and large inputs.
Convolutional autoencoders
Convolutional layers work by applying a small number of connections over an full image analyzing small segments of the larger input.
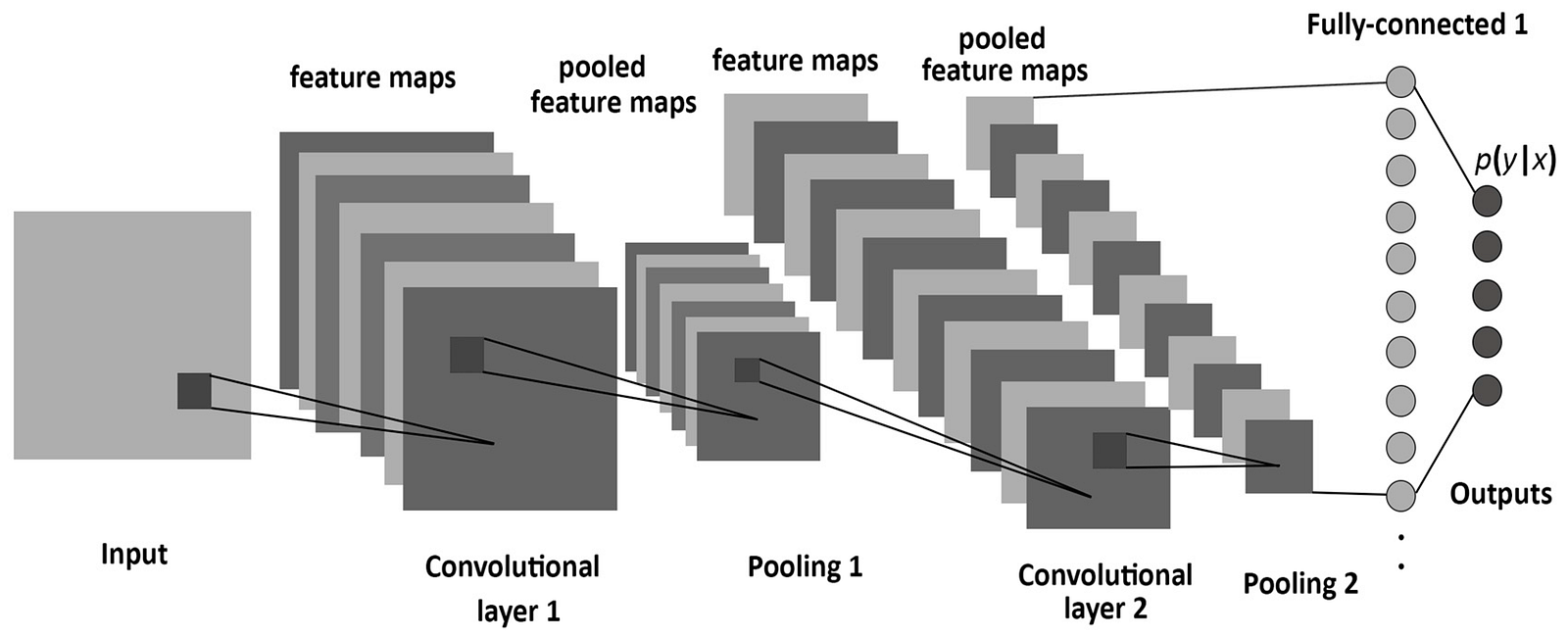
As seen in the picture only small segments of a large image are analyzed at a time. With this method very large inputs can be processed with little to no use of memory. Only about 25 neurons and connections would be simulated at a time.
I found a intresting visualization of convolutional layers in action here: http://scs.ryerson.ca/~aharley/vis/conv/
You can also read more about convolutional neural networks here https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53
Results
After training the model for about 6 hours on my CPU which was far from optimal. I reached a usable model with three layers of convolutions. This is the graph of the model I used:
This model was able to produce these results after training.
Here are some more randomly sampled results:
The model does well to reconstruct landscape features like hills, trees and even bridges / road signs however the structure of the road is not preserved well. I beleive this model can be improved on with a larger dataset and larger model allowing more features to be shown. I also plan to keep the images in color however this will triple the size of the dataset used.
Conclusions
The week was very sucsessfull in terms of progress and I think I acheived the goals I set out, I hope to continue to improve this model with color and acsess larger model complexity with GPU acceleration. This is just a starting point to the project but a lot of important milestones have already been reached.
After making the nescassary improvements to the model I will begin work on the policy making network which is the network that makes descisions about steering and controls.